Malware Engineering Part 0x1 — That magical ELF

Magic is nothing more than a logic running beyond the imagination of its audience ×_×
Since the day I got to hear about the term computer virus, I was curious to know what it exactly is or how is it created but the internet was filled with much of the random and superficial stuff about malware that it was hard to extract any useful information. Some months ago, I started with a simple file system crawler on Linux which ended up into a file infector program - Kaal Bhairav (albeit not a virus itself but capable of generating some peaceful ones). The article series is focused on crafting a simple ELF infector for disk-based infection on Linux platform (x86–64 bit INTEL architecture) which will parse the Linux filesystem and trojanize (generate segment-padded trojans) every Linux binary with a parasite code such that on execution of any infected binary (by user or system administrator), the attacker’s malicious code (parasite residing in host binary) is silently executed along with target binary’s intended execution on the host system.
Humble regards to Silvio Cesare for his paper on Unix Viruses, which is the original research documenting algorithm and implementation of Unix viruses. This project is an attempt to make his algorithm work on modern Linux systems by crafting a modern parasite (described in Part-0x3) targeting ASLR compatible software (i.e. PIE software compiled with relative offsets rather than absolute addresses). That said, it is by no means a complete reference but does contain some core concepts which may help people getting started with malware research or low-level hacking domains.
Even though the article series is written in the below mentioned chronological order, feel free to skip to whatever interests you more.
- Malware Engineering Part 0x1 — That magical ELF
- Malware Engineering Part 0x2 — Finding shelter for parasite
- Malware Engineering Part 0x3 — Crafting a peaceful parasite
First Things First
Before poking further, its better to the know the devil and his capabilities. Since we’ll be dealing with disk based infections on linux, an understanding of ELF file format is required for which we have official ELF specification describing ELF file format (link bellow). Also, interested folks can check out this ELF binaries Binary dissection course which should help in understanding Linux binaries and subsequently this article series.
- ELF Specification (Official ELF specification v1.2)
- ELF Manual ( ‘man elf’ or 5th page of Linux manual)
What is an ELF binary?
Nothing related to the world of supernatural creatures but an ELF (Executable and Linkable Format) is the standard file format for all binaries compiled on *NIX systems (i.e. UNIX based systems such as Linux). The ELF binaries on any *NIX system may be one of the 4 types -
- Executable file (ET_EXEC) —It is linker processed, ready to execute binary. Using GCC’s
-no-pieflag will produce executable with absolute addresses making it incompatible with ASLR. - Relocatable file (ET_REL)— It consists of pieces of PIC (Position Independent Code) and data that is not yet linked into an executable. Conventionally named as
*.ofiles (object files) which are not yet processed by the compile-time/static linker —/usr/bin/ld. - Shared object file (ET_DYN) — Binaries marked as
ET_DYNtype are ready to be linked within 2 views — statically & dynamically. This means that it can be combined with other relocatable or shared object binaries to create another object file (after being processed by the static linker /usr/bin/ld) or it can be linked with executable binary’s process image during load-time or run-time (by dynamic linker), i.e. getting treated as a shared library. It differs from relocatable binaries which are mostly used by compile-time linker rather than runtime linker. On modern Linux distributions almost all the system binaries are compiled as shared objects (having entry point as an offset) unlike an executable type (ET_EXEC) in which entry point is an actual address. - Core file (ET_CORE) — It is a dump of program’s process address space generated by the kernel when a crash happens or the program receives a SIGSEGV signal (Segmentation fault). It is primarily dumped for the purpose of post mortem debugging or crash analysis (using eu-readelf instead of the standard readelf program). Malware Analysts and Forensics guys might be interested in ECFS (which is an extremely useful extension to Linux core files written by elfmaster).
ELF skeleton, scary eh?
Looking at the bare bones is the best way to learn about something. Now talking about skeleton of an ELF binary, it consists of 4 main ingredients —
- ELF Header
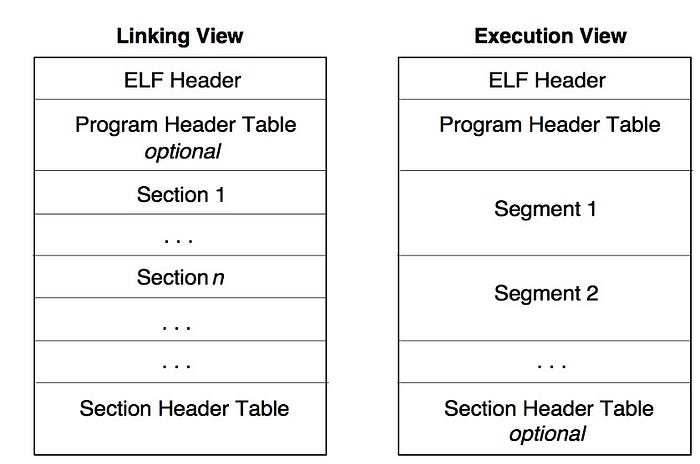
- PHT (short for Program Header Table) (provides Execution View)
- Sections (Actual Code & Data)
- SHT (short for Section Header Table) (provides Linkable View).
I’ll shortly be explaining each of the 4 ingredients in an order suitable for explanation. You can jump to the clickable links on the headings below for insights or have a look on the Linux manual for elf ($ man 5 elf) if you still don’t understand something.
ELF (Executable and Linkable Format) as the name suggests specifies 2 views — Linkable view and an Execution View. In a linkable interface, the binary present on disk is divided into logical blocks termed as sections (useful to the compiler toolchain). Execution view represents a memory view of the binary on disk, i.e. it exposes how the binary will be laid out into a process address space. A binary after getting loaded into memory is divided into logical blocks known as segments, where each segment maps to one or more sections (as seen in the linking view).
Before we discuss about sections, lets cover some more ground. Have a look at the source code below —
int shit;
void serve () { shit = 0xd3adbeef; }
int main () { serve (); }A processor doesn’t know how to deal with strings (which are just sequence of characters for human understanding) and just wishes to deal with addresses. The names used by programmer in above source (main, serve, shit) are just symbolic representations to areas in memory. Here, main and serve are both representation to areas storing code (therefore considered as function symbols) whereas shit represents data at some location (therefore considered as a data symbol). The whole task of a linker is to resolve these function and data symbols into an appropriate address locations in memory — a concept termed as relocation which applies to both compile time (for static symbols) as well as run time (for dynamic symbols) linking.
Sections — Actual code and data used by the binary is present in the form of sections which are present only in the linking view (on-disk representation) of a binary. I’ll discuss briefly about some important sections here. Knowing about other sections is of course a bonus !
Sections are a way to organize the binary into logical areas to communicate information between the compiler and the linker.
A catchy explanation taken from Computer Science from the Bottom Up by Ian Wienand pg: 147.
- .symtab : This section stores information about all the static symbols (described above) present in the binary. This section is not present in stripped binaries as static symbols are used only by the compile-time linker (ld) and not by the dynamic linker (ld.so) which does fixups during program execution.
- .dynsym : It is present only in dynamically linked binaries and consists of information about the dynamic symbols, i.e. symbols that are imported from the shared libraries or sources external to the binary. These are required by the dynamic linker during program execution and cannot be stripped from these binaries.
- .strtab : Remember, symbols are strings which the processor doesn’t like to deal with when executing a program. This section is the string table for static symbols (i.e. symbols present in .symtab section).
- .dynstr : It is the string table for dynamic symbols (i.e. symbols present in .dynsym section).
- .interp : this section stores a string pointer to the program interpreter. Isn’t it strange that a compiled program (which as per definition is readily loadable and executable by the processor) has a section defining another interpreter program on which its execution depends ?
This gets clearer as we study the process of dynamic linking. For now, this section stores the path of ld-2.xx.so which is the dynamic linker for almost all the ELF binaries on Linux. - .init : It contains the executable instructions which will get executed before the main function, i.e. used as the initialization code for the process.
- .fini : It contains the executable instructions that will get executed after the main function returns, i.e. used as the termination code for the process.
- .got : Short for Global Offset Table . It is a Table of pointers used to locate data symbols present in the binary.
- .got.plt : It is analogous to .got section but is used to locate library function symbols rather than data symbols in a binary. When a binary is loaded into memory, the dynamic-linker does some last minute relocations. Now, there’s a process called as Lazy binding (delay/lazy loading in windows terminology) which ensures that the addresses for a shared library function in .got.plt (global offset table for function symbols that are external to the binary) aren’t resolved by the dynamic-linker until the first invocation of that library function.
- .plt : Short for Procedure Linkage Table. This section stores the stub-code which is used by dynamic-linker to resolve symbols in the binary at run-time. It is used in conjunction with .got.plt section to perform lazy-binding as explained above.
- .text : All the actual executable code written by the programmer is placed in this section of the elf binary. It has access permissions of R-X (Readable & Executable but not Writable, i.e. W^X).
- .rodata : All initialized data is stored in this section having permissions of Read-Only. All constants including any format string (provided to functions like printf/scanf etc.) while compiling will be present in this section. For eg: in the statement
printf(“Hello Hell\n”);, ”Hello Hell\n” will be placed in .rodata section. - .init_array : It stores an array of pointers(addresses) to all the code blocks (or functions) which will get executed as constructor/initialization routines for the process.
- .fini_array : It stores an array of pointers(addresses) to all the code blocks (or functions) which will get executed as destructor/finalization routines for the process (i.e. will get executed just after the main() returns).
- .data : It consists of all the initialized global and static symbols defined by your code. On program execution this section is usually present in DATA segment (with Read Write permissions) of the process address space.
- .bss : It consists of uninitialized global or static symbols as defined by your code. This section is special as it does not take any space on disk (just enough space to mark its presence) and is zero initialized by its size when a program is loaded into memory. It is one of the reasons why size of file (on disk) differs from image size.
- .shstrtab : This section stores all the section names (including its own name) in the form of ASCII encoded strings. This section is will be used later to find .text section. Use
readelf -p <section_name> <binary_path>to dump strings from a section.
Section Header Table (SHT) — It describes the linking view of the binary. This table has entries for all the sections in the binary where each entry describes the respective section attributes (i.e. the section offset, type, size, flags etc.). First entry (0th index) always stores NULL, i.e. zeroed out for historical reasons (read NMAGIC, ZMAGIC and QMAGIC schemes for more details). Use $ readelf -S --wide <binary_path> to view SHT entries of an elf binary.
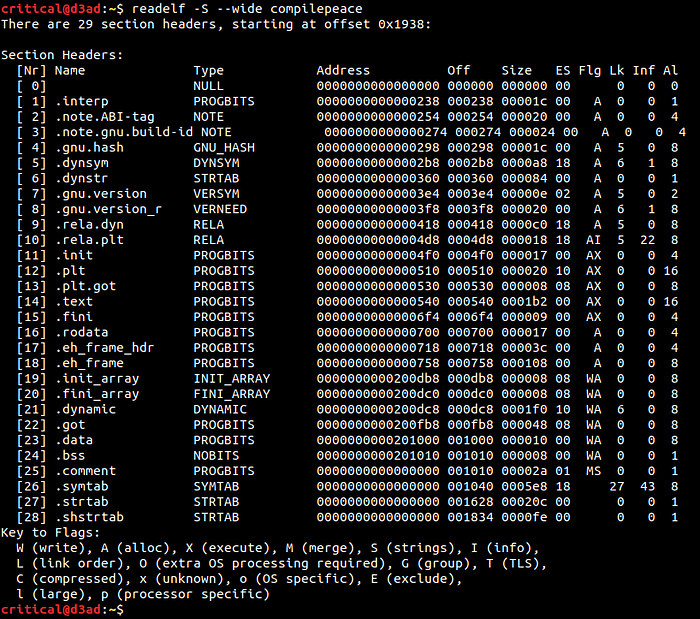
- sh_name : It stores an index. The index acts as an offset into the .shstrtab (Section Header String Table) section which stores the section names (ASCII encoded).
- sh_type : This identifies the section content and semantics. Some of the most commonly encountered section types are —
→ PROGBITS (SHT_PROGBITS) type section holds binary data defined by the program.
→ .bss section is of type NOBITS (SHT_NOBITS) which means that the section occupies no space in file (on disk).
→ static and dynamic symbols are stored in sections of having types (SHT_SYMTAB and SHT_DYNSYM).
→ relocation information is stored in sections of type (SHT_REL and SHT_RELA). - sh_addr : The section’s first byte will appear on this address (specified by this field) if the section gets loaded into memory.
- sh_offset : This field stores the offset at which first byte of the section starts in file (on disk).
- sh_size : Size of section (on disk size).
Program Header Table (PHT) — It describes the execution view of the binary. Each entry describes a segment with various attributes. It guides the operating system on how to load the on-disk representation(sections) of binary program into memory(segments) for execution, i.e. it guides the loader on which sections will constitute what segment. If PHT doesn’t make any sense to you, you may want to read this. It is placed just after the ELF Header (i.e. at an offset of 64 bytes from the beginning of the file).
Tools like readelf can interpret sections-to-segment mappings (which is created as described by the linker script). Use $ readelf -l --wide <binary_path> to view PHT entries along with section-to-segment mappings of an elf binary. Grep for Elf64_Phdr in /usr/include/elf.h for inner details about PHT structure.
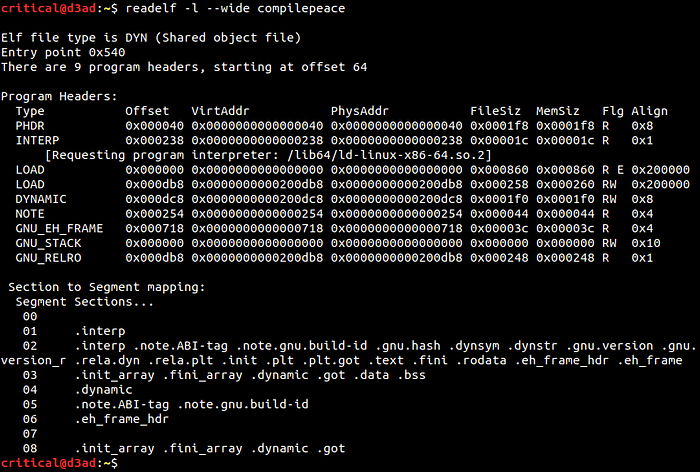
- p_type : This specifies the segment type. There are generally 2 loadable segments (specified by p_type value — PT_LOAD), i.e. code (or .text segment) and data segment.
- p_offset : Since a segment comprises of one or more sections. It specifies the offset (from the the first byte of the file) at which the first byte of segment resides.
- p_vaddr : Describes the segment virtual address, i.e. at what virtual address will the data inside the segment live.
- p_paddr : Describes the segment physical address. This field is used mainly on embedded systems which do not implement virtual memory and can safely be ignored here.
- p_filesz : Size of segment in file (on disk).
- p_memsz : Size of segment in memory. If this field exceeds p_filesz, then the remaining space is filled with zeroes at runtime (usually the case with DATA segment where space is allocated for bss segment).
- p_flags : Specifies the permission flags for a segment, i.e. PF_R (read), PF_W (write) or PF_X (execute).
- p_align : Segment alignment in memory. Segments are usually page aligned.
There are 2 segments @ 02 (CODE) and 03(DATA) that are marked as LOAD (i.e. space will be allocated in process memory for the sections present in these 2 segments). As we can see in section to segment mapping that the initialized/uninitialized global or static variables (data in .bss and .data sections) may be altered by the program code and are therefore present in the DATA segment (03) with Read+Write permissions. Similarly the .rodata section should only have Read permissions and is therefore present in CODE segment (02) with Read+Execute permissions and not in DATA segment. Also, the p_filesz and p_memsz of 03 (DATA) segment differs due to the presence of .bss section in it (which takes 8 bytes in file to mark its presence).
ELF Header — Header consists of the metadata information about the binary or simply can say that it acts as a map to the elf binary. It consists of fields which describe what type of elf binary it is (shared object, executable etc), class of binary (x86/x86–64 bit compatibility), metadata pertaining to SHT/PHT etc. It occupies 1st 64 bytes and is always present at the beginning of an elf binary. Use $ readelf -h <binary_path> to view ELF header of an elf binary. Most Important fields include -
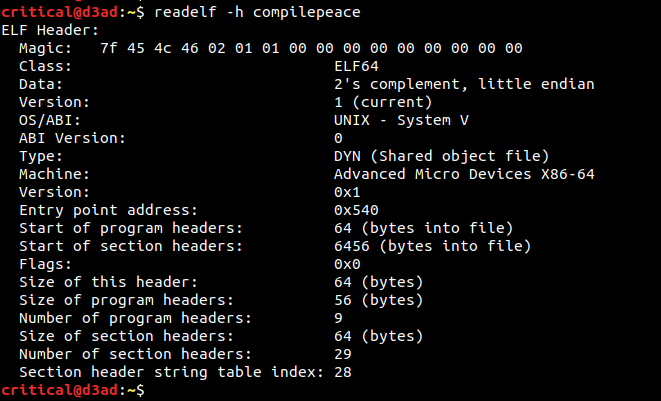
- MAGIC number (e_ident[EI_NIDENT]) : The 1st 4 bytes of a file are enough to identify a it as an ELF binary, i.e. the magic number should be 0x7f (EI_MAG0), 0x45 (EI_MAG1 or ‘E’), 0x4c (EI_MAG2 or ‘L’) and 0x46 (EI_MAG3 or ‘F’). Some more useful bytes are —
→ EI_CLASS (5th byte) defines the machine and virtual address space width, the binary is compiled for. MACROS defined are — ELFCLASSNONE, ELFCLASS32 and ELFCLASS64 (used in above example).
→ EI_DATA (6th byte) defines the data encoding (i.e. in what order is the data organized in the binary). MACROS defined are — ELFDATANONE, ELFDATA2LSB (used in above example), ELFDATA2MSB. - entry point (e_entry) : It is the location at which the code execution will start after the binary (along with all its dependencies) is loaded and all its references (relocation entries) are fixed up. This location nowadays is mostly in the form of an offset but can also be in the form of an absolute virtual address (as historically with executable ELFs). This can be used as one of the infection points that we’ll implement while hijacking control-flow of the binary.
- Binary Type (e_type) : Tells whether the executable is of Shared object, Relocatable, Executable or of Core type.
- Machine Type (e_machine) : This describes the processor-architecture for which the binary is compatible with. Our cute little parasite code (the code we’ll inject into host binary) will be written according to what processor architecture is going to run the host binary.
- SHT offset (e_shoff) : This field in ELF Header stores the offset in file (on disk) at which the first byte of Section Header Table is placed, i.e. it tells us how far is SHT placed from the beginning (1st byte) of the binary.
- PHT offset (e_phoff) : This field in ELF Header stores the offset in file (on disk) at which the first byte of Program Header Table is placed (it is usually set to 64 since PHT is stored just after ELF Header).
Other fields in ELF header including those which are useful to compute size of SHT/PHT will be needed while implementing SHT/PHT parsing functionality and therefore will be explained later in the article series.
EPILOGUE
Consider this as a basic introduction to the world of Linux viruses. Later in the series we’ll see how all this information can programmatically be accessed, extracted and tampered with to craft magical spells on system programs.
Cheers,
Abhinav Thakur
(a.k.a compilepeace)
Github : https://github.com/compilepeace
Linkedin : https://www.linkedin.com/in/abhinav-thakur-795a96157/
